Opioid Misuse Classification
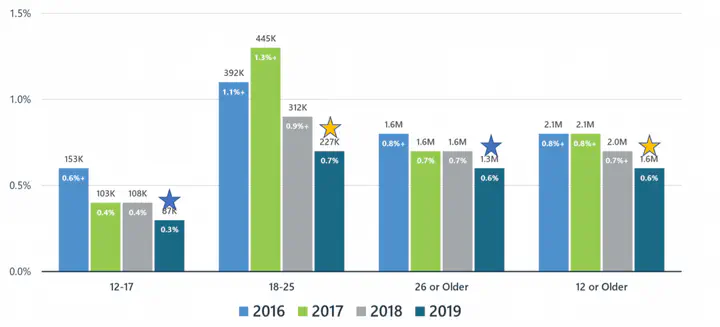 Opioid Misuse from NSDUH 2019
Opioid Misuse from NSDUH 2019In this project, we constructed several machine learning models combing with oversampling techniques for a better prediction of opioid mises for all age groups. In addition, we see the great potential of these techniques applied to a more general imbalanced data problem.
In the main modeling procedure, we fitted six Machine Learning (ML) prediction models of opioid misuse using three strategies.
- Use standard ML algorithms include Logistic regression, penalized Logistic regression, Decision Tree, Random Forests, and Multilayer Perceptron.
- The same standard ML methods are adopted, followed by the oversampling procedure.
- Employ special ML models, RUSBoost and Relogit for this imbalanced classification problem.
When evaluating the models’ performance, 10-fold stratified cross validation was implemented and AUC was chosen for the evaluation metric.
The results showed when implementing the standard ML algorithms without oversampling, the penalized logistic regression performed slightly better. Besides, RUSBoost and Relogit, special ML models for the imbalanced classification, improve the predictive models’ performance. This proved that RUSBoost (0.697) and Relogit (0.724) are more effective for the imbalanced data set.
However, after oversampling, RUSBoost and Relogit do not show a great improvement in predictive ability. All other standard ML models significantly enhanced predictive ability, especially Random Forest (0.997) and Decision Tree (0.977).
Peixuan Zhang
PhD student
My research interests include stochastic optimization, convex optimization, chance constrained optimization.